Use Machine Learning to Predict Coffee Purchase Through Data Science Platform Dataiku
Dataiku [1] is a collaborative data science platform designed to help scientists, analysts, and engineers explore, prototype, build, and deliver their own data products with maximum efficiency. The multi-deployment software has all-in-one analytics and data science system that includes integrated coding and visual interface. This allows the use of notebooks such as R, Python, Hive, Spark, and more. A customizable drag and drop visual interface may also be used at any part of the predictive dataflow prototyping process – from wrangling, analysis, and modelling.
Dataiku held a hands-on Data Science Session on 25th Feb at IDEALondon, where we worked together on a real-life retail use case, from accessing data, conducting an initial analysis of data to understand what we are working with, cleaning and preparing data before modelling and training a few machine learning models to select the best one for the problem at hand and scoring the model.
It was a very insightful workshop and we would like to share with you the process and experiences.
Case Background
A supermarket wants to understand the coffee purchase behaviours of its customers and they have a database of the past purchase behaviours of the customers.
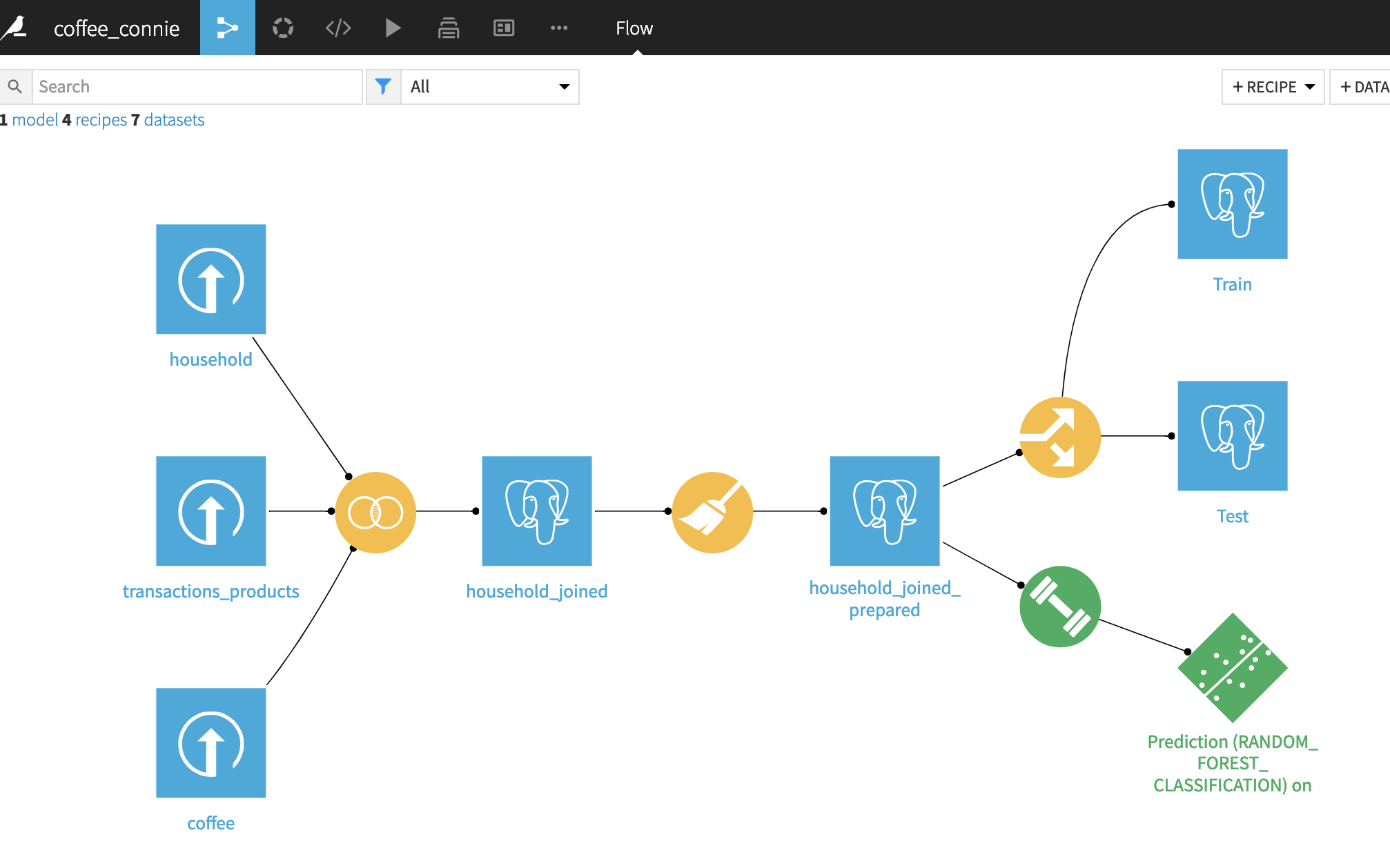
Data Pre-processing
Data cleaning tries to detect and eliminate or replace outliers and inaccurate records from the database by identifying incomplete, incorrect, and irrelevant parts of the dataset which could lead to false conclusions and would produce lower quality results. The errors in the data occur in several stages of the data collection process, for example, faulty sensors would produce false measurements or an old cashier station may have a bug and would introduce a missed record. Human errors when logging data manually also play a big part in data outliers. Using uncleaned data during the modelling and machine learning processes would mean training the models with outliers as if they would be valid records of data. This would ultimately skew the trained models to take outliers into account when making decisions, reducing their accuracy and precision.
Dataiku provides a quick statistical overview of each of the data field/column, through which we can easily identify any potential issues with the data and identify any outliers.

It also enables us to transform the data easily to meet the desired format:

Missing values is one of the most common issues with big data, and handling missing values is an important step, and we can easily manage the missing data without coding through Dataiku:

Supervised & Unsupervised Learning
There are 2 main types of learning: Supervised Learning and Unsupervised Learning.
In supervised learning, we have available data inputs and desired outputs, and the goal of supervised learning is to design a model that would fit and be tuned with input and output data in order to be able to generate similar outputs in the future provided certain combination of the input data. In unsupervised learning, we do not have output data available, which means we do not know in prior to what the models should predict. Since we only know input data, in unsupervised learning we commonly use clustering to generate N-dimensional clusters from the data, and classification process to map each set of input parameters into one of the clusters.
In this case, we know that we are looking for whether customers are going to buy coffee, and since we have a dataset that provides information about past purchases, we are able to use supervised learning in this project.
Training & Test Data Set
Because we are going to apply supervised learning, we need to split the data into two data sets: one for training and one for testing. Training data set will serve as input data for the model to learn and train from, and the test data set will evaluate how well the model performed.
A decision was made using a rule of thumb approach and we chose to use 80% of the data to training and 20% for testing:

Training Method
Dataiku offers a variety of options for professionals with different technical knowledge level to conduct machine learning and we use Quick Prototypes to get the model trained and generate results quickly:

There are many different supervised learning algorithms, and we used two of the most commonly used algorithms: Random Forest and Logistic Regression in this case.
Random forests [2] or random decision forests are an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees.
Logistic Regression [3] is named for the function used at the core of the method, the logistic function. Logistic regression uses an equation as the representation, very much like linear regression and it can be used to model the probability and make a prediction.
Results
After running the data through these two models, Dataiku gave a summary of the results and a comparison of the performance of the models. The better performing model is highlighted with trophy icons at the right-hand side, in this case, is the Logistic Regression:

Additionally, we can also easily see the table of variables importance, for example, in this case, the manufacturers’ district is the most significant variable that can predict the coffee purchase:

After running these prediction models, the probability columns will be inserted into the original table to make predictions for each customer (row), and the “1” in the prediction column indicates a high probability of buying coffee and a “0” indicates a low probability of buying coffee:

By drilling into the “prediction” column, you can easily see the distribution of “1 (buy coffee)” and “0 (don’t buy coffee)” and we can say that around 44% of the customers will buy coffee in their next purchase in the supermarket.

References:
[1] https://reviews.financesonline.com/p/dataiku-dss/
[2] https://web.archive.org/web/20160417030218/http://ect.bell-labs.com/who/tkh/publications/papers/odt.pdf
[3] https://machinelearningmastery.com/logistic-regression-for-machine-learning/





